A little bit about resilience testing in Go
Introduction
What are resilience tests? This is tests which covers unusual application behavior, for example: database outage, message broker outage and so on. This kind of tests may sounds very important, but usually I didn’t wrote them for my applications previously. I think that a lot of developers didn’t created them too, because:
- Priorities were feature development
- E2E/IT tests were already created and them already tests infrastructure, so there is no reason to create dedicated tests for infrastructure failure
- Infrastructure failure is rare case, so there is no reason to spend efforts for cover this cases and a lot of another similar reasons, why we should skip resilience tests.
A reason “Priorities were feature development” is completely OK for skip resilience tests, because business money is not infinite, so I will not cover this reason in a my post. But another two reasons will be covered in a this post.
Usual E2E/IT tests covers infrastructure outage
No them not covers, main purpose of this tests are cover functionality of an application. And them tests application in a good conditions when database connection is alive which is not always a case in real production runtime. Usually tests don’t cover loosing connection and then restoring connection and process business flow, but this conditions are usual for runtime. To have a possibility to test application resilience I can’t rely on usual E2E which tests business flow, I need create separated E2E which tests application resilience.
Infrastructure failure is rare case
Previously I think and heard a lot of this words:
- Infrastructure failure is rare
- If we will have outage of X we will have more problems rather than outage of Y, so there is no reason to think how to handle outage X
This words are partially right, but what if I say that infrastructure failure is not so rare, this is a common thing for modern applications? What if I say that we can think about handling outage of X to reduce downtime for our users and eliminate chain downtime of our services?
Resilience tests can make a software system more robust and decrease times for wake up developers at 3 A.M. to fix production environment and even more them can make users happy by reducing services downtime, because applications will know how to handle infrastructure downtime.
Theory sounds good, but in this post I will explain only how to write E2E test which will test loosing of connection to a message broker and then restoring it. To do so I created simple service which accepts HTTP requests and publishes message to a message broker.
Service overview
An example service contains a simple HTTP endpoint which receives a request and sends it to NATS message broker. Business case of service: IoT device sends telemetry information to an example service.
I chose NATS as example of infrastructure component which can have an outage during system runtime, because NATS client has very interesting property: after lose a connection with NATS broker client tries to retry and when retry limit was reached client moves to CLOSED state and never tries to retry again. Which means that service which used NATS client goes to permanent outage, because service can’t restore connection with NATS message broker by default NATS client configuration. I already saw service outage with loosing NATS connection some time ago, that’s why I chose a NATS as example.
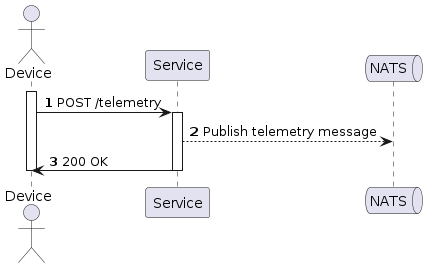
Test cases
To test resilience of the service above let’s describe test cases
Service loose a NATS connection and republishes messages after restoring connection
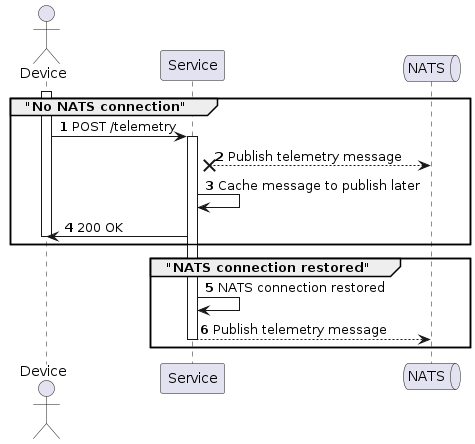
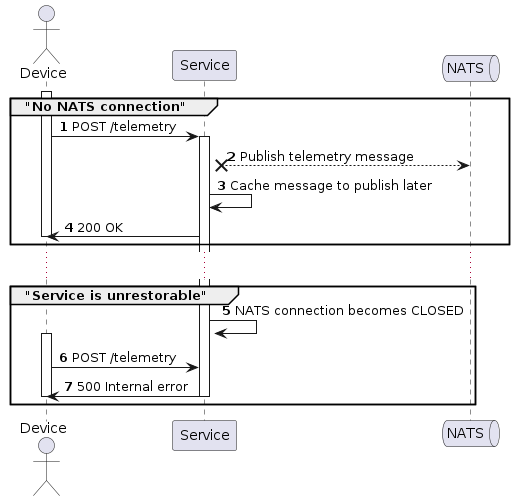
Service loose a NATS connection for long time and becomes unrestorable
Testing tools
To test cases described above I should somehow simulate loosing NATS connection. To do this I will use Toxiproxy which gives a possibility to add delay, simulate disconnect and another defects to TCP connection.
Tests architecture
Service loose a NATS connection and republishes messages after restoring connection
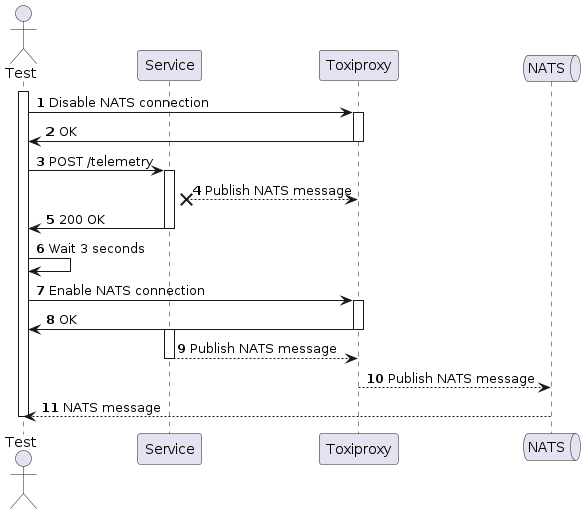
Test code
Code at GitHub.
t.Run("publish NATS message after restoring connection to NATS", func(t *testing.T) {
stage := test.NewStage(t)
stage.NatsIsUnavailable().
SendTelemetryRequest()
stage.TheResponseIsSuccessful().
TheNatsMessageWasNotPublished()
stage.After5Seconds().
NatsIsAvailable().
TheNatsMessageWasPublished()
})
Service loose a NATS connection for long time and becomes unrestorable
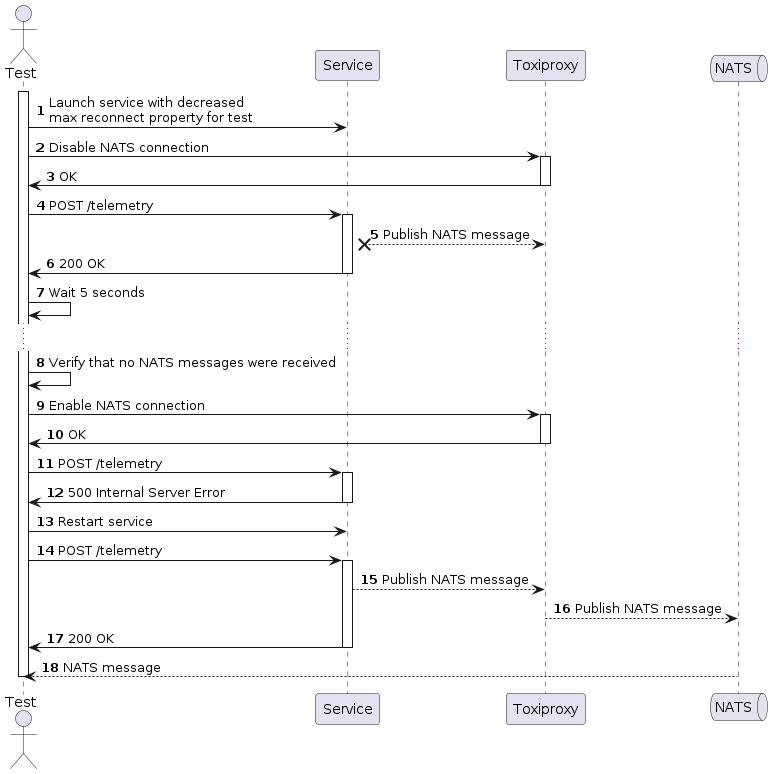
Test code
Code at GitHub.
t.Run("send NATS message after loose NATS connection and then restart service", func(t *testing.T) {
stage := test.NewStageWith3NatsReconnect(t)
stage.NatsIsUnavailable().
SendTelemetryRequest()
stage.TheResponseIsSuccessful().
TheNatsMessageWasNotPublished()
stage.After5Seconds().
TheNatsMessageWasNotPublished().
NatsIsAvailable().
TheNatsMessageWasNotPublished()
stage.SendTelemetryRequest().
TheResponseIsInternalServerError().
TheNatsMessageWasNotPublished()
stage.RestartService().
SendTelemetryRequest().
TheResponseIsSuccessful().
TheNatsMessageWasPublished()
})
Toxiproxy
Get or create proxy to NATS
Code at GitHub.
func getOrCreateNATSProxy() *toxiproxy.Proxy {
toxiClient := toxiproxy.NewClient("http://localhost:8474")
p, err := toxiClient.Proxy("nats")
if err == nil {
return p
}
p, err = toxiClient.CreateProxy("nats", fmt.Sprintf("0.0.0.0:%d", natsProxyPort), "nats:4222")
if err != nil {
panic(err)
}
return p
}
Enable proxy
Code at GitHub.
func (s *Stage) NatsIsAvailable() *Stage {
err := s.natsProxy.Enable()
if err != nil {
s.t.Fatal(err)
}
return s
}
Disable proxy
Code at GitHub.
func (s *Stage) NatsIsUnavailable() *Stage {
err := s.natsProxy.Disable()
if err != nil {
s.t.Fatal(err)
}
return s
}
Conclusions
Tests described in post gives a possibility to verify that service can restore connection with NATS or in case if service can’t restore it, after restart a service everything works. Of course that there is loosing of events in current architecture, but my purpose was just to show that resilience tests exists and them can be helpful for test how service works with infrastructure outage.